some LLM evaluation keywords explained

What does 0-shot CoT Maj@32 means?
skip to the end for recap and answer
When evaluating the capabilities of LLMs on tasks like question answering, researchers often use benchmarks consisting of carefully curated sets of questions (for an example check out the “GPQA” benchmark which I discovered recently… it just amazed me).
The performance of the models on these benchmarks is then reported using various metrics and techniques. When you check out models system cards three important terms you’ll frequently come across in this context are “x-shot,” “CoT,” “pass@1” and “Maj @ 32”
x-shots
The term “x-shot” refers to the number of examples or context provided to the LLM in the prompt before the actual question or task. It is therefore an indication of the prompting description
For instance: 0-shot: No examples are provided, testing the model’s ability to answer the question without any context. 5-shot: Five examples related to the task are provided as context before the question. The more examples (or “shots”) provided, the easier it becomes for the model to understand the task and potentially perform better. However, 0-shot evaluation is useful for assessing the model’s general knowledge and reasoning abilities without relying on specific examples.
See this medium article for a quick visual understanding and check out this paper for more.
CoT
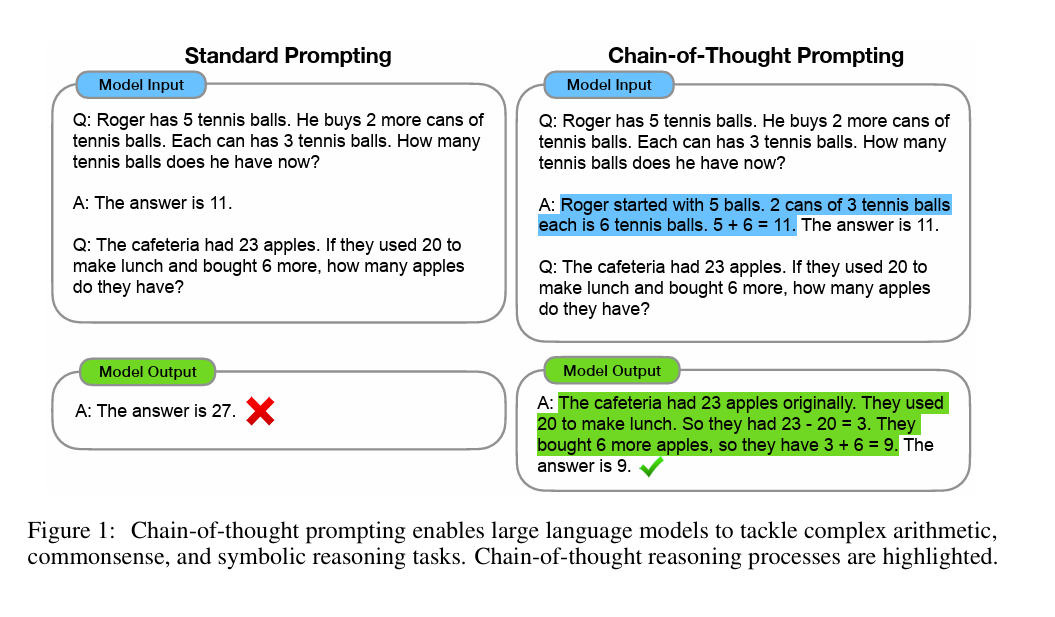
Chain of Thought (CoT) prompting is a technique that encourages the LLM to break down a problem into step-by-step reasoning before arriving at the final answer check out the original Google Brain Meeting. As such it is a prompting indication. Instead of directly outputing the answer, the model is prompted to show its thought process, which can reveal valuable insights into its reasoning capabilities, and more importantly improve model performance.
This is why adding “think step by step”, “verify step by step, and such variants, are a good (prompting hack)[https://www.youtube.com/watch?v=wVzuvf9D9BU&ab_channel=AIExplained].
This approach helps assess the model’s true capability by allowing it to structure and reason through complex problems, rather than just its ability to spit straight the correct final answer.
Pass@x
Pass@x refers to an evaluation metric as opposed to referring to an instruction description such as CoT and x-shot. “pass@1” simply indicates the percentage of answers the model gets the correct at first try, “pass@10” is the percentage where at least 1 in 10 attempts were correct.
Pass@1 evaluation is useful for coding tasks where the primary goal is to obtain the correct code, and there is no need to define other specifications regarding prompting technique.
One such example is the Mostly Basic Programming Problems, where the dataset does not allow/require different prompting strategies (i.e. no think step by step there).
Maj @ x
Maj@x also refers to an evaluation metric. This refers to a majority voting mechanism used in the evaluation of responses generated. This mechanism is employed to assess the robustness and consistency of the model’s outputs across multiple attempts.
When a language model generates multiple answers for the same question (for instance, 32 different attempts or “runs”), the “Maj@32” metric would evaluate whether the majority of these attempts agree on the same answer. Essentially if you have are asking a true or false question, you would need more than half of the model answers to be correct to consider the model to be right, if you have a multiple-choice question with 4 possible options, you would need the model to choose the correct option more than any other option with a minimum of 5 times. If you have an open question, the model should converge to the correct solution most of the times.
This approach helps in determining the reliability of the model when tested many times and provides a higher bound on the capability of the model testing its boundaries potential.
Recap
Think of an LLM like a student. “Shots” are the examples you attach to the question in the prompt for the LLM to learn from.
- Zero-shot: You simply ask the LLM a question.
- One-shot: You give the LLM one example preprended in prompt.
- Few-shot: You provide a handful of examples preprended in prompt. The fewer shots an LLM needs to understand a task, the better it usually is.
CoT stands for “Chain of Thought” and is a hack to improve model performance by encouraging to show its working step-by-step. This forces it to have a longer reasoning in terms of tokens before jumping to the answer, decreasing the chance of unlucky sampling.
For pass@1 we are checking if LLM’s first answer attempt solve the task correctly. A high pass@1 score means the LLM is accurate and nails the answer quickly.
Maj@32 measures a model’s capacity by checking if over 32 attempts the most frequent answer is the correct solution.
Therefore, when evaluating an LLM using “0-shot CoT Maj@32” we are looking at the success rate of the model, when prompted with a question with 0 examples prepended and with “think step by step” or similar variants appended, and the success is based on whether over the 32 replies to such prompt, the majority of the answers converge on the same solution.